
Machine Learning and Go at GopherCon 2018
I was able to attend the machine learning and go workshop at GopherCon this year. It was neat.
Here are my notes.
GopherCon 2018 - Machine Learning w/ Go 🧠🤛🏽
@dwhitena datadan.io sil.org - changelog.com/practicalai - ardanlabs.com
Diana @dicaormu Xebia - women who go Paris
Materials
GitHub - ardanlabs/training-ai training-ai/machine-learning-with-go at master · ardanlabs/training-ai · GitHub
Goal
Help eng / programmers learn ML and how to integrate it Not to become AI researcher
Intro
Log in, grab docker and run a Jupiter notebook
docker run -it -p 8888:8888 -v /home/pachrat/training-ai/machine-learning-with-go:/notebooks gopherdata/gophernotes:gc2018
To make this easy, the organizers have create a docker image with Jupyter and a Go kernel for Jupyter called gophernotes.
Connect to notebook, run some simple examples.

Notebooks have a terminal option, on the right hand side - New -> Terminal
Can do a go get from there to bring in a 3rd party package.
ML and the Model development workflow
Take input, apply model, provide output Input is unknown / raw
Data in -> Modeling relationships -> data out
Modeling is equations / parameters - a function!
f(data in) = data out
features -> model -> labels & response
Want to fit the equations to a particular use case.
Training data - a set of proven examples - can help provide parameters and adjust the model. You don’t know the best parameters to reach the proper output / labels. “Teach” the model based on existing examples and use that to set the “best” parameters. This is the Training process.
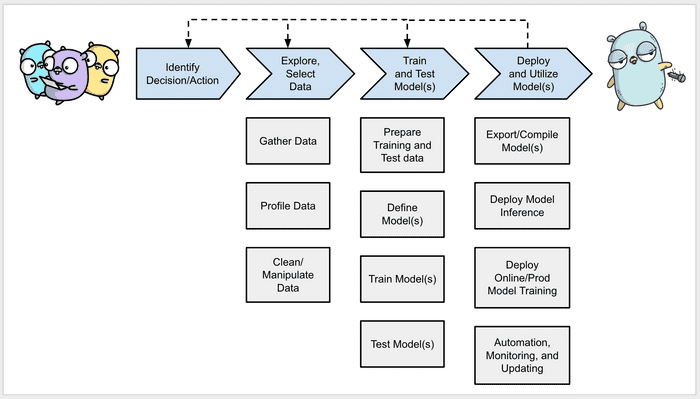
Training is iterative - iterate over all the examples/training data.
Inference is the process of turning data in, applying the model and getting data out. When you have the parameters and model, you can now provide new data and get output.
Congrats! You are now ML engineers. ;)
Use Cases
You need a use case. “Identify decision/action”. Anomaly detection (i.e. network traffic that stands out).
Highly repetitive action that needs to be taken over and over again. If well defined and existing examples - that’s an ideal problem for ML.
Traditional approaches in prediction / classification require an expert who understands the domain and can tweak parameters. Humans are biased and have faults. Example: guess the population of Namibia ML does not remove bias from scenarios.
ML models are highly specific to a certain task. Can augment what people are already doing. Ask yourself, “Where are you doing something repetitive that can speed up or augment what you are already doing?”
Evaluation - provide test examples and evaluate how model performs. Have to validate model once it starts providing output. Can save some of your training data and do quality control on that set. Can also do cross-validation. Want to mimic reality (I.e. if 5% of emails are spam, then don’t use 75% of validation data that is spam)
ML With Go
Jupyter notebook - ml_with_go/example1
Jupyter throws an * in until it is done, then shows a number to show when that block was executed.
training-ai/machine-learning-with-go/mlwithgo/example1 at master · ardanlabs/training-ai · GitHub example1 shows how to load input files, convert to Go struct’s and do some basic reading and input/output.
training-ai/machine-learning-with-go/mlwithgo/example2 at master · ardanlabs/training-ai · GitHub example2 now uses a csv of athlete weight, height, age, etc. Want to predict weight based on height.
lunch break
GopherData · GitHub - org for data science-y things in go
Solution using alt regression package - notebooks/ml_with_go/solutions/solution1.ipynb
GitHub - gorgonia/gorgonia: Gorgonia is a library that helps facilitate machine learning in Go.
gonum has a number of good packages
resources/tooling at master · gopherdata/resources · GitHub
This is a curated list of well-maintained and developing tools, packages, libraries, etc. related to doing data science with Go.
Discussion around go vs python, how to share models across langs,
Example 3 - Classification / Clustering
Regression is about modeling changes based on changes in other variables.
Hyper parameters - # of neighbors to check, # of levels of decision tree (?) If you had 10-15 parameters, can be computationally expensive to try them out. In a neural network, the # of nodes in a layer, the number of layers, etc. Hyper parameters are choices made to help decide what is best. Not part of training data (i.e. width / height).
Cross validation - a series of experiments. Split training and test data randomly, then run and output a metric. Then, do that again. Run thru your entire set of training data as an experiment.
Probabilistic inference ?
Measure range of metrics/output and use that to perform quality analysis on model. Run the model multiple times and you’ll know range of performance.
Example 4 - Clustering
notebooks/ml_with_go/example4/example4.ipynb
ML Workflow
Given data, put in a patients features, predict the progression of the disease.
/training-ai/machine-learning-with-go/ml_workflow
Try the template and see if you can get it working.
Once you’ve trained the model and have the data (or need to tweak the model) - what do you do next? Need to version and QA the model.
Build a pipeline!
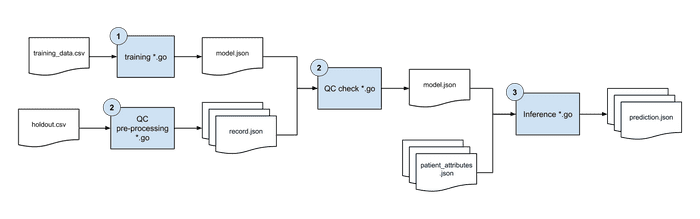
Example of Coke’s app that scans for codes on a bottle cap. If it can’t identify or user auto-corrects, then that goes into training data set.